The Linguistic Trajectories of Presidential Candidates
Polls and Primaries
I’ve been fascinated by the current presidential electoral cycle in Colombia. Beyond my personal stake in the process, a lot of interesting things have happened, and the way media and citizens have tried to make sense of the situation has been compelling. As has become a trend in recent election cycles, the presidential field started with a high number of precandidates—too many for any citizen, even the most sophisticated ones, to track consistently. Additionally, the enforcement of new regulations on survey polling during election periods and the increased use of participatory mechanisms to select candidates and build coalitions likely have implications for the discoursive space. What’s more, it’s a competitive election: two candidates sit on top, with a surprisingly interesting race for third place and its implications for negotiation in the run-off1.
How could we get a peek at the linguistic dynamics in play? One way to study the discourse in a field is to think about the frames of reference that elites communicate to the citizenry2. Most citizens first encounter concepts in discoursive space—candidates, issues, events—through elite communication of some sort, whether through traditional channels like news media or more contemporary ones like social media. These concepts then take on a life of their own, with the meanings used to frame them evolving once individuals interpret and deploy them. Still, looking at the frames used in media gives a good estimate of the space.
So, we want to study the relevant concepts being used in the field and their meanings as the electoral cycle is in full throttle. In a context with so many moving parts, what are the meanings and narratives that citizens can use to make sense of the field? A La Carte (ALC) Embeddings are a good tool to explore this puzzle.
I used this as an opportunity to practice using word embeddings and teach myself some more methods. I leave the code used to train the model and develop the analysis in case anyone finds it useful. I wrote a jupyter notebook with the same analysis alongside the code that generates the figures with commented code.
A word on word embeddings
Word embeddings operate under a simple but powerful idea: the meaning of a word can be inferred from the company it keeps—the words that regularly appear around it. If you represent a word as a vector based on how often it shows up near every other word in a corpus, you end up with a numerical representation of that word’s meaning. These vectors capture semantic relationships in ways that are often surprisingly rich: words that are close in vector space tend to be close in meaning. We can train a model on a specific corpus so that the meanings particular to that context become detectable and measurable. I’m a personal fan of the method.
A La Carte (ALC) embeddings take this a step further. Traditional approaches learn a fixed vector for each word across the entire training corpus. ALC embeddings, by contrast, let you build representations from particular subsets of text (i.e. all articles published in a given week.) This makes them a particularly good-fit for studying how the meaning of words shifts over time or varies across contexts.
So, if we want to see the frames of reference that people are being “offered” to navigate the political landscape, we could use ALC embeddings to look at the meanings associated with each candidate, how they relate to one another, and how they connect to salient issues.
Data
I scrapped all articles in the politics section of El Espectador from august 2022 to january 2026. This results in 129100 articles, covering all of the current presidential period. We get some context about how candidates were being talked about before the election cycle started in full. The scraping code is available here.
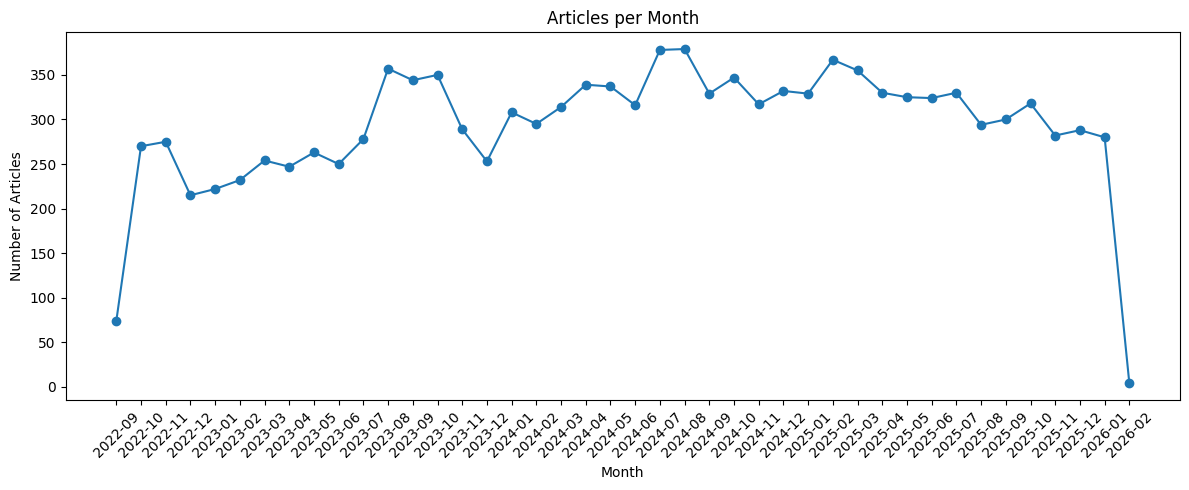
Barring the first and last months of the period, we have a solid number of articles per month.
Before training the model we need to do some preprocessing beyond basic cleaning. The model only tracks individuals, so we need to turn candidate names (which are composed of many words) into single words. The best way to do so is to convert mentions of each candidate into name_lastname so that word2vec interprets it as a single token. For the sake of interpretability, and my own sanity, I limit the analysis to candidates that are scheduled to participate in interparty consultation or those that polled anything in, at least, five polls.
I process the text and look at how candidate mentions are distributed in the corpus over time. For now, I focus on candidates that, according to the last poll I saw, have any chance to make it to the first round ballot.
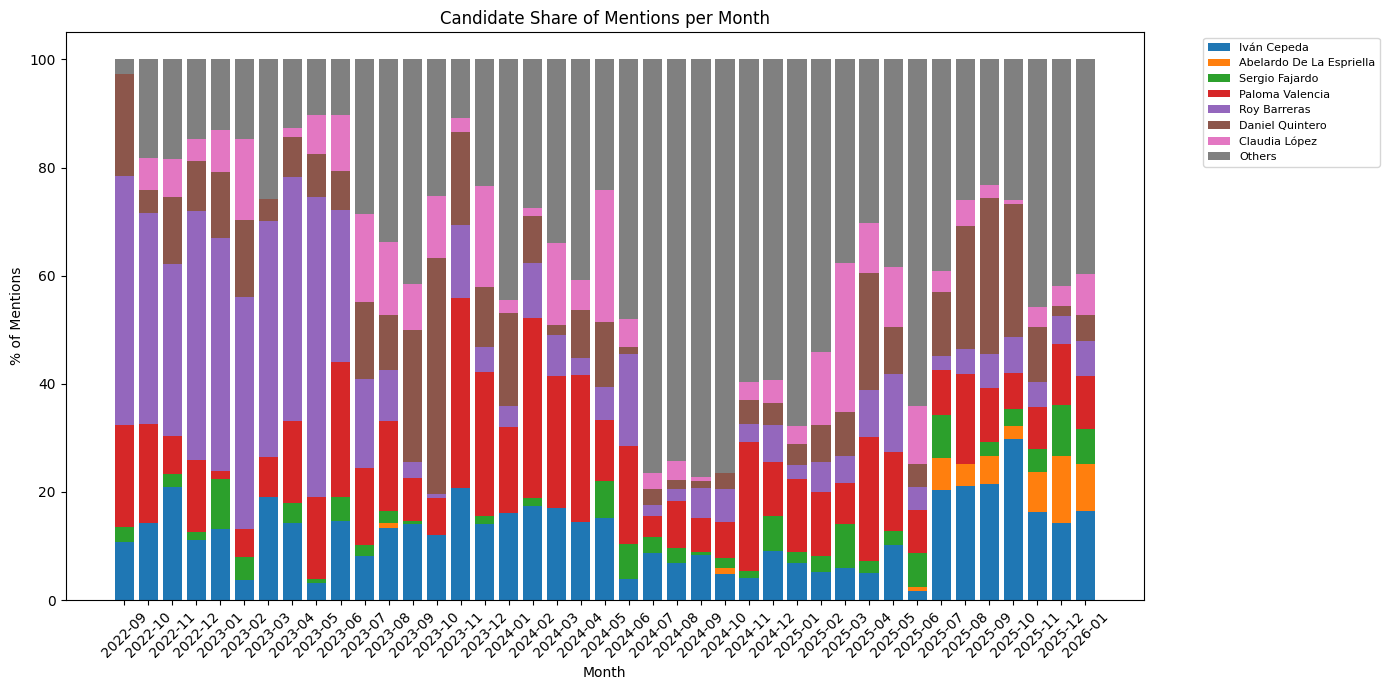
Interesting. For how strong he is polling, De la Espriella became a common fixture in political news relatively recently. The optimist in me hopes this suggests that he will deflate soon. The rest of the top candidates are regular fixtures in the political arena, so it is not surprising that they dominate in mentions.
Embeddings
I use these articles to train a Word2Vec model basing the parameters on Rodríguez and Spirling (2022)3. The model contains the vectors for 26624 unique words. We can use it get an initial sense of the meaning given to candidates in the corpus by looking at the most similar words to each of them based on their cosine similarity.
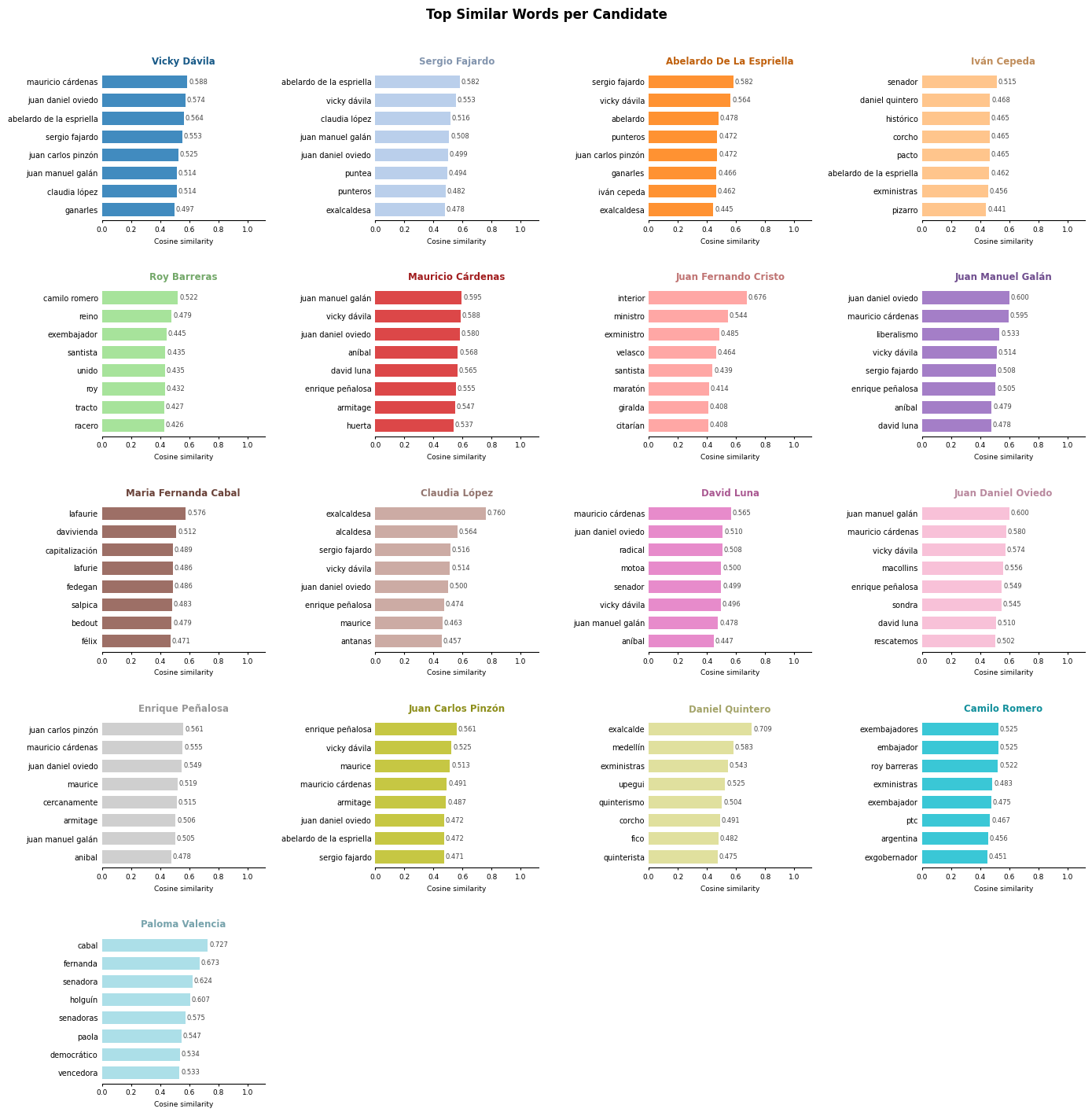
Again, some interesting stuff here but nothing super surprising. Candidate meanings seem to coalesce around each other as alliances and consultations pop up. This is particularly true for candidate that are polling low (See Vicky Dávila, Mauricio Cárdenas, Enrique Peñalosa, and other members of La Gran Consulta por Colombia).
It is somewhat expected that candidate vectors are similar to each other. Being candidates in a presidential election cycle is a big similarity in itself. This is a valid finding, but it does not say much about the frames of reference being used for candidates beyond “candidate.” ALC embeddings allows us to dig deeper into candidate vectors and the discoursive space.
ALC Embeddings
For every word $w$ in the vocabulary, compute its context vector $\bar{c}_w$ (average of its neighbours’ embeddings over the full corpus). Then find the linear map $A$ such that $\bar{c}_w \cdot A \approx v_w$ via least squares. This transform can then embed any word—or a candidate in a specific time window—given only its context. This method has been show to produce high-quality embeddings for use cases such as this one4.
Let’s go back to the original question: How does the meaning that media gives to candidates change over a time period? Using ALC embeddings, we can collect all context windows around each candidate-month pair token in that month’s articles, average them into a single context vector, and apply $A$ to get the ALC embedding for that candidate-month pair. This time labeled embeddings are then a representation for the evolving meaning of candidate as the electoral cycle goes on.
To control for outlier months and reduce the noise of the model, I calculate each candidate-month embedding as the rolling average of the last three months. This erases the uniqueness of each month, but it takes into account that candidate framings are given in context and usually respond to a larger window of considerations than a month. A more thorough analysis would have to test the robustness of this transformation.
We can visualize these trajectories by locating each candidate-month vector in a reduced version of the discoursive space. To do this, we use a dimensionality reduction algorithm, such as t-SNE. t-SNE (t-distributed stochastic neighbor embedding) is a technique that reduces the dimensionality of the vectors from 300 dimensions to 2, making it so that they can be placed on a 2-dimensional plot. Relative distances are mostly preserved, so we can assume that words that appear closeby in the plot, are also close in our high-dimensional discoursive space5.
Interpreting distances in high-dimensional spaces can be tricky. Concepts that have a lot in common but have culturally-salient differences (e.g. man and woman) are oppositional while concepts that have truly nothing in common (e.g. man and staircase) are orthogonal. In embedding spaces, orthogonality leads to higher distance than oppositionality, even though the latter is more relevant to us6. Sometimes the more interesting distances are not the largest.
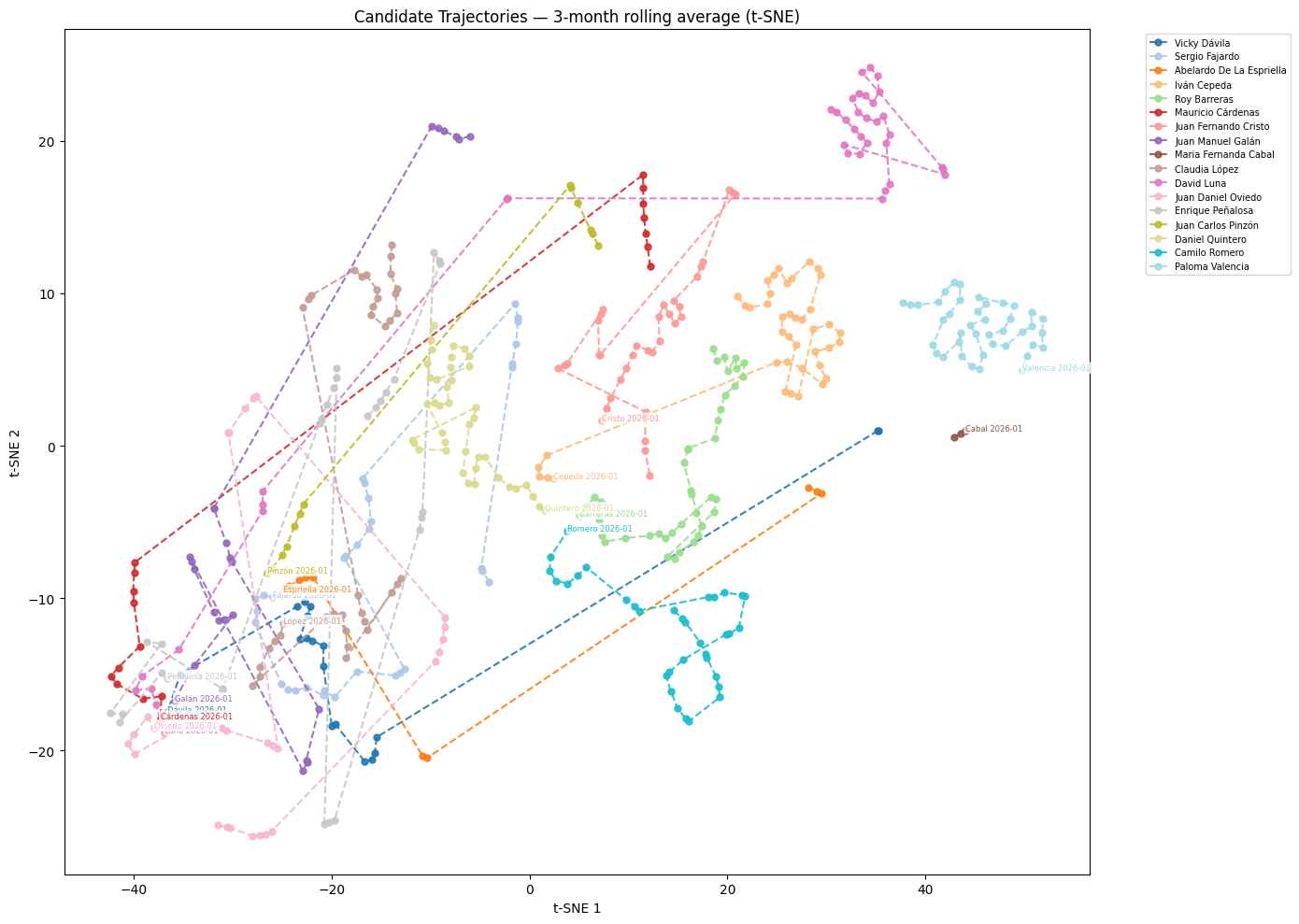
This is much more informative than a static representation of the global model. Let’s try to make sense of some trajectories.
Coalitions and meaning convergence
Looking at where candidates end up at the end of the period, we can pretty easily infer the two clusters of candidates representing the two most competitive consults. We see a convergence in semantic trajectories from candidates in the left (Camilo Romero, Roy Barreras, Daniel Quintero, Iván Cepeda and Juan Fernando Cristo) around the center of the plot, and a big convergence of candidates in the center-right (Juan Manuel Oviedo, Vicky Dávila, Juan Manuel Galán, Mauricio Cárdenas, and David Luna) in the bottom-left of the plot. In both cases, the candidate word vectors are close to each other in the final month that I have data on, but we can see that this convergence is not random but the result of a month-by-month trajectory.
My theory is that this is a result of coalition building via consults. I begun this post talking about the increased used of participatory mechanisms for candidate selection. From a strategic point of view, it makes sense why a political group would use them. Candidates in pre-election consults receive additional attention from a media apparatus that may be ignoring them , and by signalling closeness to other candidates, the winner of the mechanisms hopes to gather the votes of the losers. The strategy also aims to simplify citizen decision making by creating salient groupings of candidates and it seems that it works in the sense that the semantic offering in media representation also coalesces around candidates in consults.
The technocratic centrists, Sergio Fajardo and Claudia Lopez, also end up close together in semantic space. There were rumors about them going into a consult that ended up not happening, but we can see the results of media speculation in the plot.
Semantic leaps and becoming a candidate
I have a harder time interpreting some of the massive shifts in position that we see from a couple of candidates. Interestingly enough, all jumps seem to be moving in a similar direction. There are probably methods out there to infer an interpretation of the dimension but this post is long enough. If we consider that most of the candidates that “leap” occupied very specific and prominent roles in the landscape at the beginning of the period, where the presidential candidacies are not a determinant factor.
In this theory, candidates move a different region in the meaning space to a more generic “candidate” meaning space. Vicky Dávila and Abelardo de la Espriella go from prominent outsider to the candidate region, while David Luna and Iván Cépeda go from being senators to candidates. I feel particularly good about the senator region interpretation as we see both Paloma Valencia and Maria Fernanda Cabal around there. The data scrapping was done before Paloma Valencia became the official candidate of the right-wing party Centro Democrático, so maybe if were to get more data we would see a similar leap.
Abelardo de la Espriella
He is the biggest story in this electoral cycle. A controversial lawyer following the playbook of the Milei, Bukele and other latin american neolibertarians. Big on AI, performative masculinity and harassing journalists. Like with many unapologetic, right-wing outsiders, the media does not know what to do with him.
In his case, we are only interested in the later part of the period, few expected him to be a presidential front runner in august 2022. His leap into the candidate semantic region is logical in that sense, but being that close to Sergio Fajardo and Claudia Lopez, who have openly distanced themselves from him, is weird.
Maybe the ALC embeddings are able to capture the hard time that traditional news media, such as El Espectador have when trying to conceptualize this type character.
Footnotes
-
At the time of writing. March 4th, 2026 ↩
-
J. Zaller (1992). The Nature and Origins of Mass Opinion ↩
-
Rodriguez, P. L., & Spirling, A. (2022). Word embeddings: What works, what doesn’t, and how to tell the difference for applied research. The Journal of Politics, 84(1), 101-115. ↩
-
Rodriguez, P. L., Spirling, A., & Stewart, B. M. (2023). Embedding regression: Models for context-specific description and inference. American Political Science Review, 117(4), 1255-1274. ↩
-
t-SNE is a dimension reduction technique focused on visualization. We should not do any analysis on this reduced coordinates, but they work great for illustrative purposes. ↩
-
Amir Goldberg - The Sociology of Interpretation. A Computational Approach ↩